
 推荐应用
推荐应用
样本即用型试剂盒:含ATAC-seq实验中除样本以外的所有试剂,无需额外其他组分(注:因index种类较多,index需额外配备,index货号17265ES,该货号最多有384种搭配组合)。
组织样本需搭配12514/12516ES进行细胞核提取(组织细胞核提取试剂盒)。
植物样本需自行处理成细胞核样本后再搭配12208使用。
Hieff NGS® ATAC-Seq Library Prep Kit for Illumina®是针对Illumina®高通量测序平台研发的用于ATAC-Seq实验的文库构建试剂盒,适用于100-100,000个细胞起始量的样本建库。ATAC-Seq(Assay for Transposase Accessible Chromatin with high-throughput sequencing)技术能够利用Tn5 转座酶识别染色质开放区域,快速有效的反映表观遗传状态。经过细胞收集及裂解、转座酶片段化、磁珠回收片段化DNA、文库扩增和磁珠分选等步骤,DNA片段最终转化为适用于Illumina®平台测序的文库。
本试剂盒包含两个独立模块:BOX-I和BOX-II。BOX-I为提取DNA的DNA Extract Beads和回收文库的DNA Clean Beads,BOX-II包含细胞裂解、片段化以及后续文库扩增所需的所有试剂。此外,本试剂盒已在不同种类样本(如K562、MCF-7细胞,小鼠肝脏等)中进行了验证,均具有良好的建库效率和建库产量。本试剂盒提供的所有试剂都经过严格的质量控制和功能验证,最大程度上保证了文库的稳定性和重复性。
●含两种纯化磁珠:针对小片段纯化,回收效果更好。
●实验操作简单、实验周期短:建库一步法,节省建库时间;
●样本投入量低,投入量兼容范围广:能兼容100~10万个细胞投入。
●实验重复性好
产品应用:ATAC-seq、染色质开放性研究、转录因子鉴定、足迹分析等
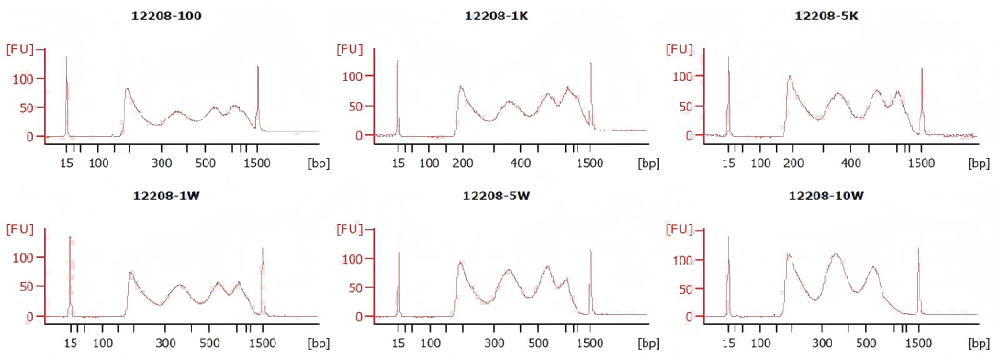
1、不同细胞投入量的ATAC建库结果一致性较高
293细胞ATAC建库,细胞投入量从100个到10万个,不同细胞投入量建库后,文库峰型以及IGV可视化结果一致性较高。
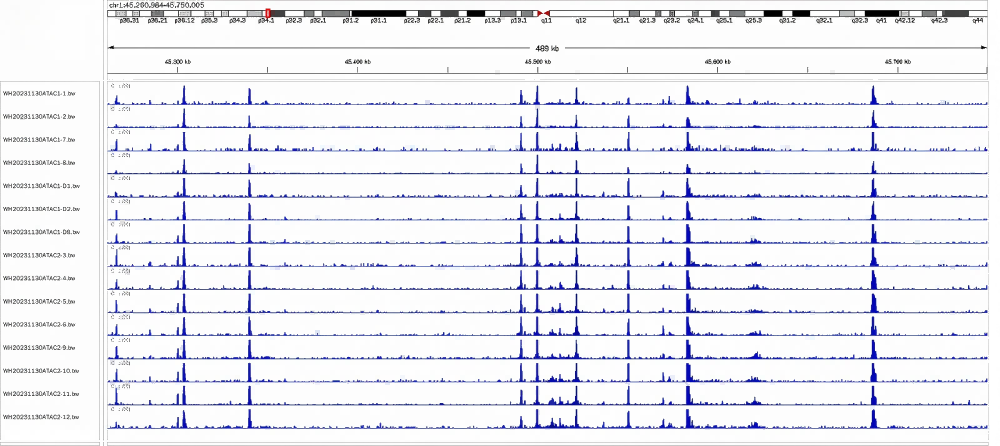
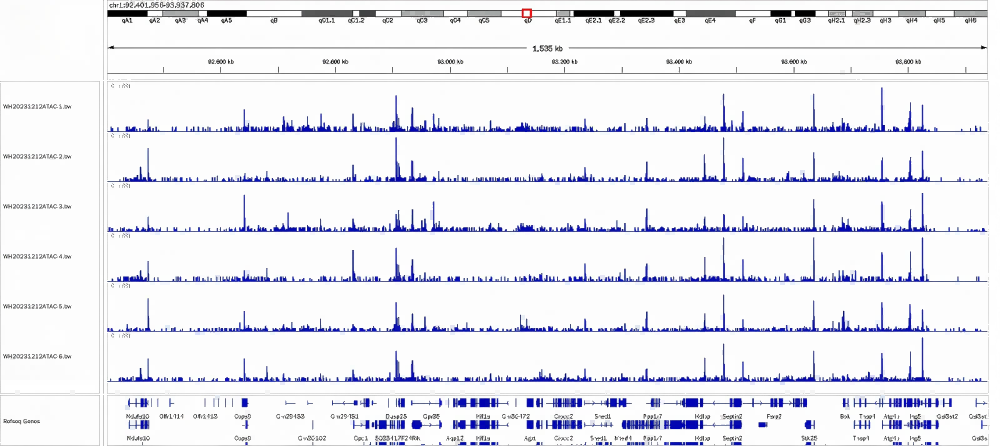
2、冻存样本ATAC建库结果展示
对不同冻存时间的样本进行ATAC建库,目前测试冻存20天内的样本建库无问题,且测序结果信号明显。
冻存样本要求:尽量客户样本保存在液氮中,如果保存-80℃冰箱,需要无反复冻融情况。

BOX-I:2~8℃保存。
BOX-II:-25~-15℃保存。
【选购指南】表观遗传系列产品选购指南
19106
2026-03-30
【应用方向】酶切法建库试剂盒全面赋能多领域应用研究
13843
2025-08-06
【技术讲解】NGS建库神器 | 转座酶建库全流程拆解,5分钟看懂!
12596
2026-05-12
【选购指南】RNA建库系列产品选购指南
13230
2026-03-30
【选购指南】DNA建库系列产品选购指南
6071
2026-03-30
【应用方向】表观组学专题:ATAC-seq,你了解多少呢
12146
2025-06-05
【前沿资讯】上新|保姆级ATAC建库试剂盒,轻松carry表观建库
6564
2025-08-04
【应用方向】实验法宝放送——冻存样本如何做ATAC
13340
2025-07-15
【技术讲解】精准片段化赋能ChIP实验|翌圣微球菌核酸酶MNase,ChI 实验标配神器
464
2026-05-29
【应用方向】植物ATAC实验流程
11907
2026-04-16
【前沿资讯】限量试用 | 抢先体验MuA转座酶:突变克隆子制备、环状DNA克隆的首选工具!
18418
2025-06-18
【应用方向】带你认识伴刀豆球蛋白A磁珠
7695
2025-08-05
【前沿资讯】干货|TadA脱氨酶:开启m6A检测的新篇章
9886
2024-06-13
【前沿资讯】翌圣ZymeEditor™转座酶系列产品全面助力NGS文库构建
15937
2025-09-08



